VulHawk Cross-architecture Vulnerability Detection with Entropy-based Binary Code Search
一篇二进制代码相似性检测(代码重用)的文章,但面向的是 IoT 平台,看看它是如何解决碎片化编译和跨架构的问题的
在二进制代码相似性比对/搜索的工作中,使用神经网络和自然语言处理处理来表征汇编代码的方法已经较为成熟,但过往的工作(例如 Asm2Vec 和 PalmTree)大都只能处理单一架构的汇编代码,或者采用多架构训练的方式处理多架构的代码。相对来说,binary lifting 的思路对训练集的依赖更少,但也带来了更多的隐式指令(条件寄存器)和无关指令,增加了分析的难度。
此外,考虑到 IoT 的场景,二进制代码在 指令集架构(x86,arm,mips) / 指令集字长(32-bit,64-bit) / 编译器(gcc,clang) / 优化级别(O0,O1,O2,O3,Os,Ofast) 四个维度都存在自由组合的可能,即一共有 72 种可能。即使是相同的源代码,在经过不同编译工具链组合下产生的二进制代码也相差很大。如果要任选两种组合进行比较的话,则有 2556 种场景,很难用单个系统来解决。
综合以上两个难点,本文提出了一种新的 IR function 模型,并利用信息熵理论将 2556 种场景归约为 71 种表征转化问题,提出了 VulHawk 模型来进行二进制代码搜索。和二进制代码比对相比,代码搜索需要进行一对多的比较,对于比对速度有更高的要求。
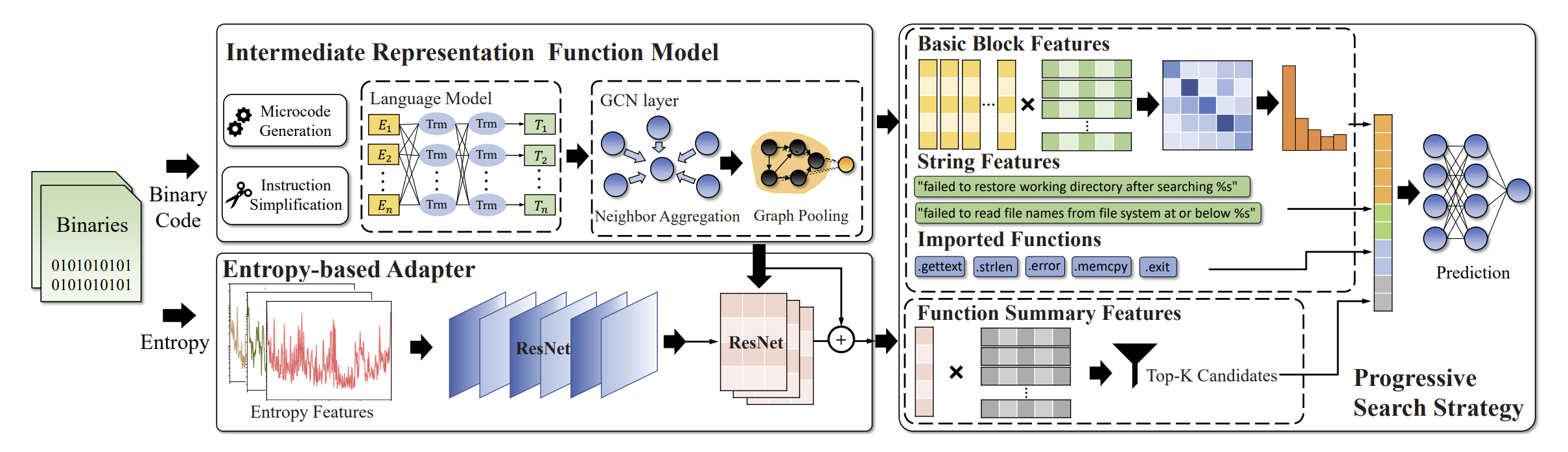
VulHawk 的整体流程如上图所示。首先,VulHawk 用 IDA Pro 提取出跨架构的 Microcode,随后使用 opcode left right dest 的模型来分词,并引入自定义的 opcode 来解决 Out-of-Vocabulary 的问题。VulHawk 采用了 RoBERTa 的 NLP 模型,在预处理部分,VulHawk 对经过分词后的 Microcode 进行了分类和指令简化。在指令简化前,先显示地构建出操作 EFLAGS 的指令,随后以(1)全局变量和内存中的变量(2)函数返回值(3)子函数调用参数 三类指令为标记,依据 def-use 关系进行指令简化。经过简化后的指令如下图所示,某种意义上达到了反编译的效果,减轻了后续神经网络的负担。

在预训练阶段,VulHawk 针对 Microcode 使用了 Masked Language Model (MLM), Root Operand Prediction(ROP), and Adjacent Block Prediction (ABP) 三个模型。在生成 BasicBlock 的 embedding 之后,VulHawk 再结合 CFG 信息,喂给 GCN 模型后,得到 Function 的 embedding。
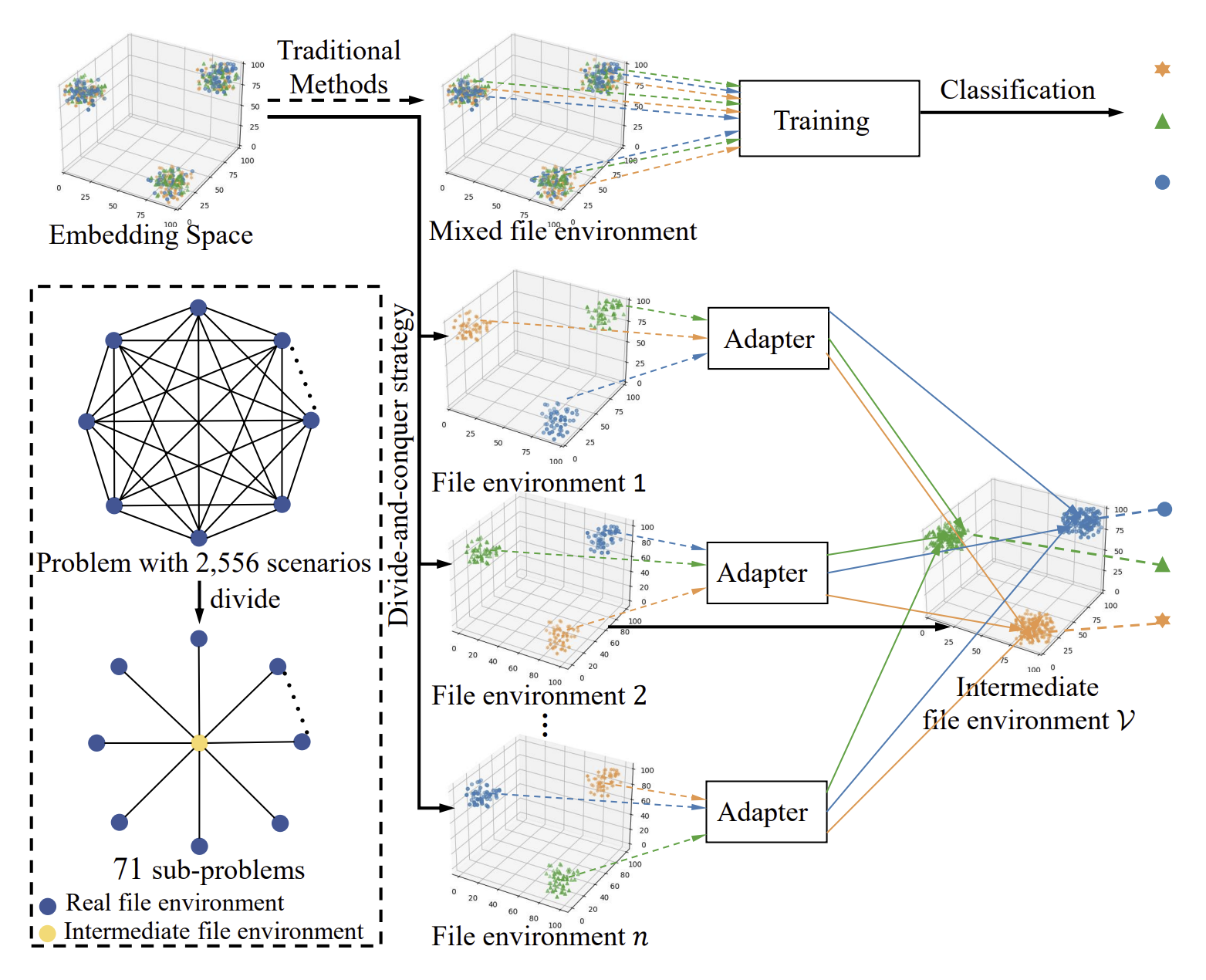
随后是对不同编译工具链组合的处理,VulHawk 使用了分治的思路。首先,作者使用信息熵来区分出不同的编译工具链组合,如下图所示,即使是在不同的项目中,信息熵也可以起到很好的区分效果,使用 ResNet 来识别信息熵图即可。作者使用 O1-GCC-x86-64 作为一个中间对象,定义了 71 个转移函数,将其他编译工具链组合的生成的 Function embedding 转移到中间对象上再进行比较。

在得到了同一的 embedding 之后,作者还采用了渐近式(progressive)的搜索策略。第一阶段,先根据 Function embedding 进行搜索。但考虑到函数内部 minor patch 的场景,很多时候需要细粒度的信息,VulHawk 再次收集了 BasicBlock 和字符串常量等信息进行精细化的比对。
实验阶段,VulHawk 设计了 6 个实验:
- 在一对一,一对多,多对多场景下的搜索情况 -> 都表现优异,超过 SOTA 。。。
- 在大型代码库下的运行情况(性能和效率)-> 在 2s 完成 10^6 级别的函数搜索
- 不同阶段/组件对整体效果的影响(ablation study)-> 基于信息熵的分类是最有用的
- 对于真实世界 1-day 漏洞的搜索情况,使用了 20 个物联网设备,选取 OpenSSL 和 Curl 的 12 个历史CVE,进行一对多搜索
参考链接
- https://www.ndss-symposium.org/ndss-paper/vulhawk-cross-architecture-vulnerability-detection-with-entropy-based-binary-code-search/
- https://github.com/RazorMegrez/VulHawk